
(python에 있는 시각화 패키지 seaborn을 이용합니다)
데이터 불러오기
저는 캐글에 있는 타이타닉의 train.csv 데이터를 가지고 시각화 해보겠습니다.
Titanic: Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
www.kaggle.com
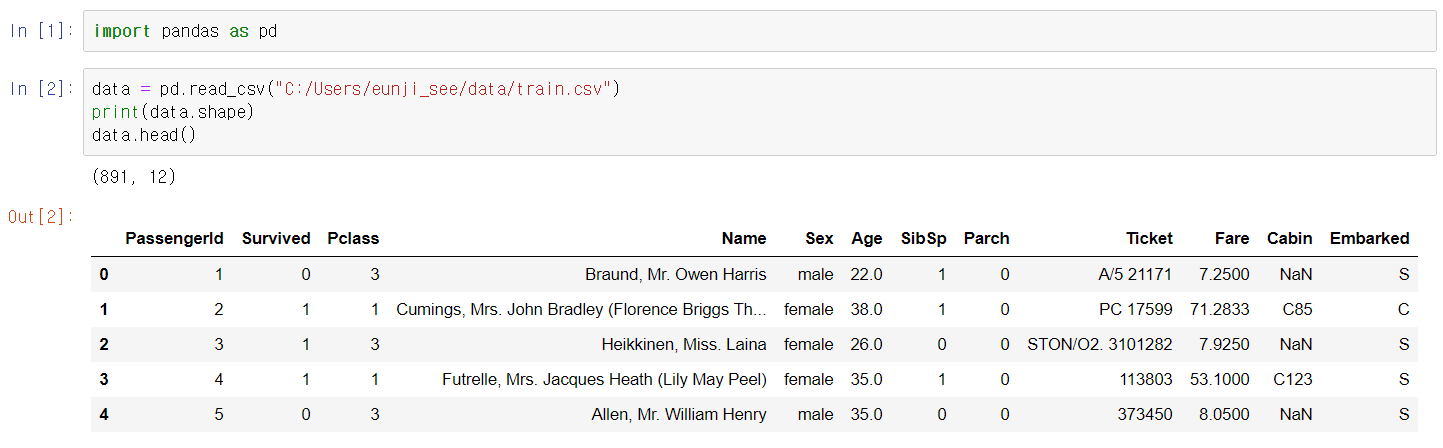
데이터 정보 : 타이타닉 사고 당시 생존자(Survived=1)와 사망자(Survived=0)의 정보가 나와있는 데이터입니다.
시각화 준비하기
시각화 패키지를 사용하기 위한 기본 세팅입니다.

사용할 데이터가 한글로 이루어져 있을 경우 아래와 같이 설정해주어야 합니다.

저는 윈도우 10을 쓰고 있습니다 ('Malgun Gothic')
Mac 이용자는 'Apple Gothic' 하시면 됩니다.
한글로 설정 안하면 아래와 같이 네모로 나옵니다.
시각화 그래프의 기본 종류를 알아보도록 하겠습니다.
1. countplot
데이터의 수를 알아보고 싶을 때
'Sex'컬럼에는 'male'과 'female' 두 가지 value가 있고 이를 분류해 그 수를 카운팅해 보여줍니다.
'Sex'별 데이터(row)의 수
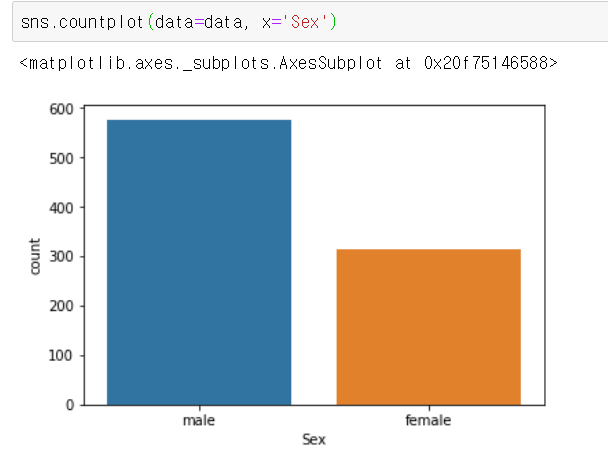
당연한 말이지만 countplot의 y축은 항상 count 이기 때문에 y축을 따로 설정할 수 없습니다.

hue를 지정하면 분류가 한 번 더 들어갑니다.
* hue에 넣으려는 컬럼 value의 종류가 너무 많으면 깔끔한 시각화를 만들 수 없습니다.
* 3종류 이상 넘어가면 bar가 너무 많아지기 때문에 그래프가 지저분해질 확률이 높습니다.
* 컬럼 value의 종류란? ex) 'Survived'컬럼은 0과 1 로 value가 두 종류입니다.
'Sex'별 생존자와 사망자의 수

압도적으로 남자가 많이 죽었음을 알 수 있습니다.
2) distplot
평균치를 나타내주는 정규 분포입니다.
타이타닉 승객자의 나이 분포도



선은 전체적인 흐름을 볼 수 있고
히스토(바)는 각 나이마다 구체적인 정보를 알 수 있습니다.
3) barplot
x별 y의 평균치를 보여줍니다.
'Sex'별 'Age'의 평균

'Sex'별 'Age'의 평균에서 생존유무('Survived') 추가

4) boxplot
객실의 등급(Pclass)별 'Age'의 분포
* 박스의 정중앙이 (검정선과 별개로) 평균값(mean)
* 검정선은 중앙값 (median)
* 평균은 말그대로 n분의 1로 평균을 낸 것이고, 중앙값은 숫자를 1~100까지 나열했을 때 중앙에 있는 값.
(ex. 대한민국 사람들의 평균 연봉은 3500만원이라는데 이는 고액 연봉자가 평균 값을 올려놔서 그렇습니다.
중앙값을 따져보면 2000~2500일 것입니다. )
* 박스의 정중앙에 검정선이 오지 않는다면 평균과 중앙값이 일치하지 않는다는 말, 즉 아웃라이어가 있거나 데이터가 불균형하다는 말입니다.
* 다이아몬드는 아웃라이어.
* ㅗ와 T자는 최소, 최댓값

5) pointplot
대체로 x축이 서로 연관성이 있을 때 사용합니다. (ex. 나이, 시간 등)
* 연관성이 없을 때는 barplot을 사용합니다.
* 보통 시간의 흐름에 따른 어떠한 양상을 보고 싶을 때 pointplot을 씁니다.
타이타닉에는 시간 컬럼이 없어 다른 데이터를 통해 보여드립니다.
시간의 흐름에 따른 저의 체중 변화입니다.
날짜가 겹쳐서 안 보이네요.

lineplot을 쓰면 모든 날짜를 표시하지 않고 부분으로 끊어서 보여줍니다.

마찬가지로 hue옵션을 넣을 수 있습니다. (lineplot은 hue옵션이 안 됩니다. 이유는 저도 모르겠...)
'Age'와 요금('Fare')에 따른 생존 유무

갓난 아기들은 거의 살았고 10세 이하 아이들의 생존 유무는 요금의 높낮이와는 상관없어 보입니다.
그러나 10세 이상 부터는 요금을 많이 낸 사람이 거의 90% 이상의 확률로 생존했다는 사실을 알 수 있습니다.
6) scatterplot
x축 y축 이외에 더 많은 조건들을 추가할 수 있습니다.
hue = 해당 컬럼에 따라 색을 지정합니다.
size = 해당 컬럼에 따라 동그라미 크기를 지정합니다.
sizes = 동그라미 크기의 사이즈를 지정합니다.

요금이 올라갈수록 생존자가 많고 거의 다 1등급입니다.
사망자의 대부분은 요금을 적게 낸 3등급 승객이라는 것을 알 수 있습니다.
슬프네요..ㅠ
데이터 시각화 종류에 대해 정리해보았습니다.
아주 기초적인 부분만 정리해놨습니다.
그래프의 사이즈 조절, 컬러, 다양한 추가 옵션들을 지정할 수 있습니다.
시각화의 종류를 필요에 따라 알맞게 골라 쓰는 것도 데이터 분석의 중요한 능력 중 하나입니다.
아직 많이 멀었지만 데이터 분석을 요리조리 꾸준히 하다보면
자연스럽게 터득하게 되지 않을까 싶습니다.
데이터 분석하시는 분들 모두 홧팅입니다.
'데이터 방' 카테고리의 다른 글
| 자기 분석 프로젝트 (0) | 2019.09.18 |
|---|---|
| 워드 클라우드 만들기 (주피터노트북 _ 파이썬) (11) | 2019.07.30 |
| 체중 변화 분석 ( +판다스 데이터 시각화) (0) | 2019.07.09 |
| 데이터 분석 (체중관리 3차) (0) | 2019.07.07 |
| 데이터 전처리 기초 (1) | 2019.06.26 |



