판다스의 핵심이자 가장 기본인 DataFrame을 배워보자.
DataFrame 생성하는 것부터, 어떤 기능들이 있는지 살펴볼 예정이다.
판다스로 하는 데이터분석의 시작 - DataFrame

1. DataFrame 생성하기
data = [['2020-01-01','150','google'],['2020-01-02','120','naver'],
['2020-01-03','110','naver'],['2020-01-04','125','daum'],
['2020-01-04','117','google']]데이터프레임은 기본적으로 엑셀과 같은 테이블 형태다. 직접 데이터프레임을 만들 때에는 이렇게 행과 열의 수가 맞도록 리스트를 작성해주면 된다.
data = pd.DataFrame(data)데이터프레임으로 만들어주면,
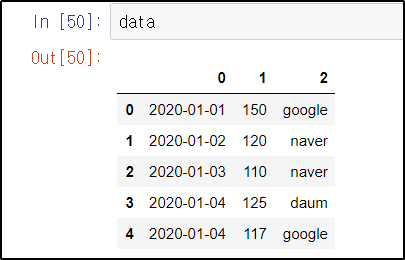
이렇게 행과 열의 형태로 데이터프레임이 생성된다.
2. 열 이름 넣기 (열은 판다스에서 column이라고 말합니다)
data = pd.DataFrame(data, columns = ["date", 'visit', 'site'])컬럼 이름을 넣으려면 데이터프레임으로 변환하는 코드를 작성할 때 옵션으로 넣어주면 된다.
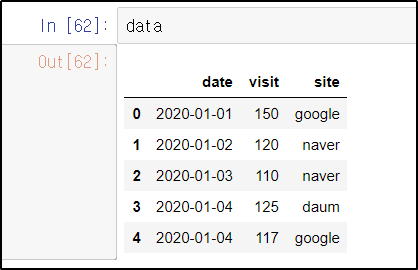
* 애초에 컬럼을 넣어 데이터프레임을 생성하고 싶다면 list와 dictionary를 함께 사용한다.
(데이터프레임을 만들고 컬럼을 추가하는 방식보다, 애초에 컬럼을 넣어서 데이터프레임을 만드는 방법이 더 안전)
1) 딕셔너리 안에 리스트를 넣는 방법.
data = {
'date': ['2020-01-01', '2020-01-02', '2020-01-03','2020-01-04','2020-01-05'],
'visit': [150, 120, 110,125,117],
'site': ['google','naver', 'naver','daum','google'],
}2) 리스트 안에 딕셔너리를 넣는 방법.
data = [
{'date': '2020-01-01', 'visit': 150, 'site': 'google'},
{'date': '2020-01-02', 'visit': 120, 'site': 'naver'},
{'date': '2020-01-03', 'visit': 110, 'site': 'naver'},
{'date': '2020-01-04', 'visit': 125, 'site' : 'daum'},
{'date': '2020-01-05', 'visit': 117, 'site': 'google'}
]두 방법 모두 <결과2>와 동일하게 데이터프레임이 생성된다.
3. DataFrame의 기본기능 - 판다스에서 기본적으로 제공하는 몇몇 기능들을 알아보자.
우선 임의로 날짜별지출 이라는 데이터 프레임을 만들었다.
날짜별지출 = [
{'date': '2020-01-01', 'expense': 20000, 'state': 'good'},
{'date': '2020-01-03', 'expense': 10000, 'state': 'good'},
{'date': '2020-01-03', 'expense': 15000, 'state': 'good'},
{'date': '2020-01-05', 'expense': 13000, 'state': 'good'},
{'date': '2020-01-07', 'expense': 35000, 'state': 'not good'},
{'date': '2020-01-09', 'expense': 40000, 'state': 'not good'},
{'date': '2020-01-09', 'expense': 20000, 'state': 'good'},
{'date': '2020-01-10', 'expense': 22000, 'state': 'good'},
]
name =["임월드", "김남편", "임월드", "임월드", "김남편", "김남편", "김남편", "임월드"]
# name은 날짜별지출 데이터의 인덱스가 될 이름이다. 날짜별지출 = pd.DataFrame(날짜별지출, index= name)
이렇게 데이터프레임 형태로 변환할 때 옵션값으로 index = name으로 넣어주면
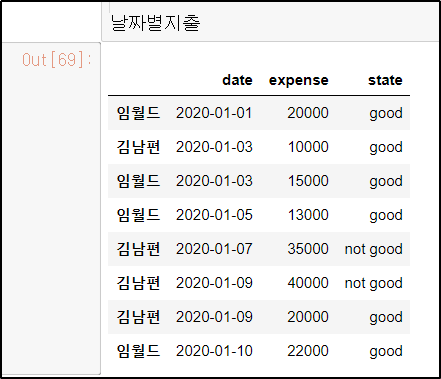
이렇게 행(index)자리에 이름이 생긴다.
* 출력된 결과를 보면 판다스 DataFrame은 크게 세 가지 요소로 구성되어 있다는 것을 알 수 있다.
행(row 또는 index) , 열(columns), 값(values) / 각각 판다스 기능을 사용하여 불러올 수 있다.
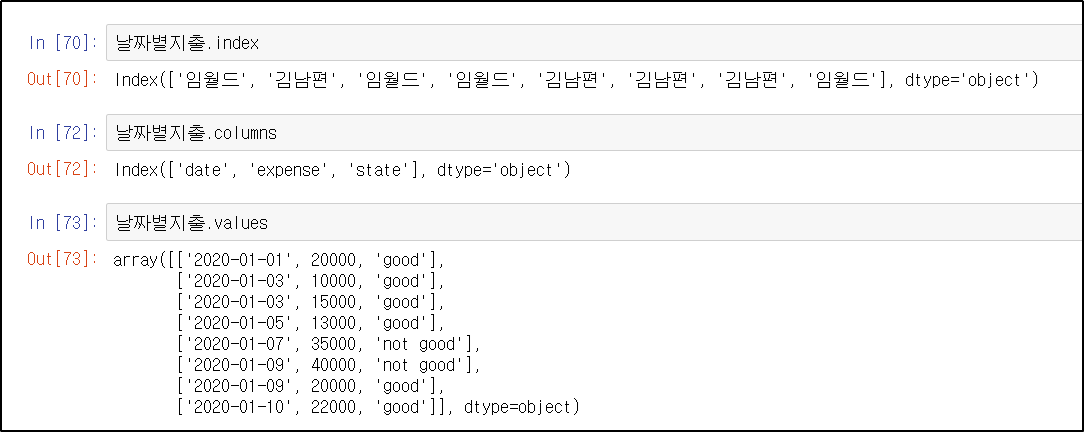
참고로 원하는 값들을 한꺼번에 출력해보고 싶다면 print기능을 이용하면 된다.
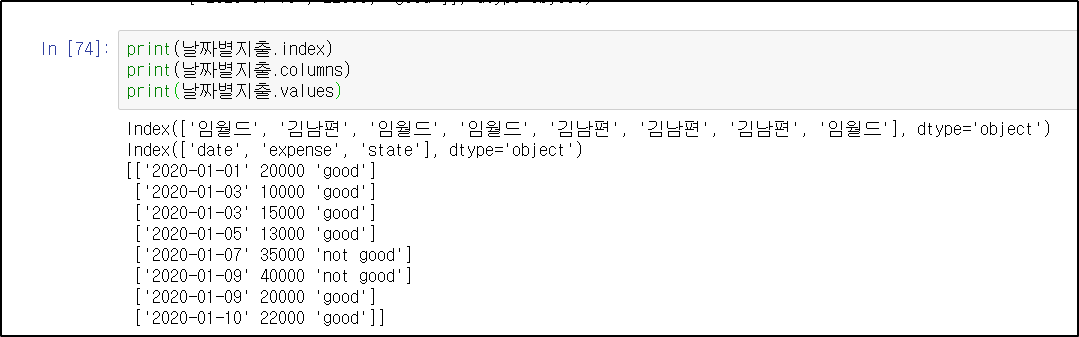
4. 컬럼명 바꾸기(.columns)
데이터프레임 이름에 .columns를 입력하고 바꾸고 싶은 컬럼명을 리스트 형태로 저장한다.
날짜별지출.columns = ["날짜", "금액", "상태"]
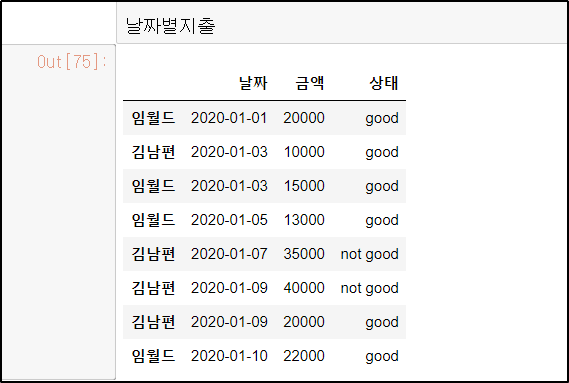
5. 데이터 일부만 보기 (상위=head, 하위=tail)
날짜별지출.head(3)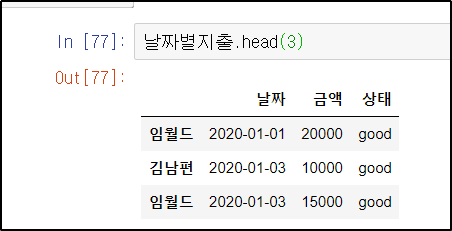
괄호 안에 아무 숫자도 넣지 않으면 5개가 출력된다.
6. 데이터 정렬하기(.sort)
1) 행(index) 정렬하기
날짜별지출.sort_index()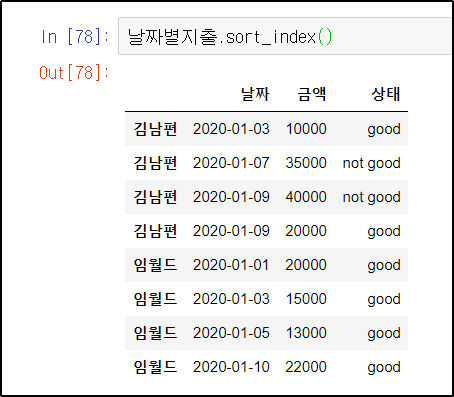
이름 순으로 정렬되었다.
* 숫자는 작은 순(0 ~ 9)으로 알파벳은 A부터 Z까지 정렬. 대소문자가 섞여있을 경우 대문자가 앞으로, 소문자가 뒤로 온다.
2) 열(column) 정렬하기
날짜별지출.sort_index(axis=1)기본 코드에 axis=1 옵션을 넣어주면 된다. 행을 정렬할 때는 axis=0이라는 기본 옵션이 디폴트 값으로 들어가있기 때문에 따로 작성하지 않아도 된다.
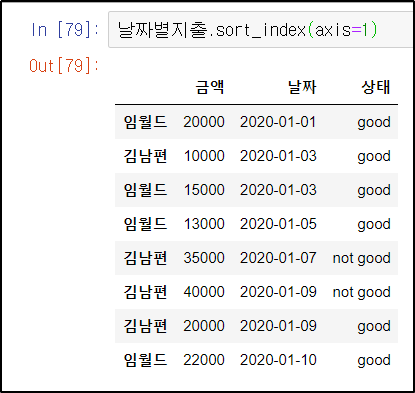
컬럼명이 금액-날짜-상태 순으로 정렬된 것을 확인할 수 있다.
*정렬 순서를 바꾸고 싶다면 기본 코드에 ascending 옵션을 넣어주면 된다.
날짜별지출.sort_index(axis=1, ascending= False)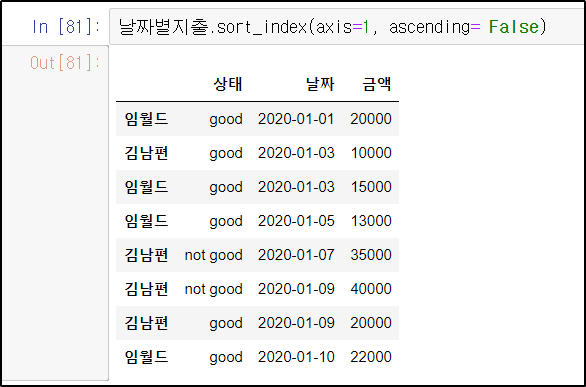
컬럼명 순서가 거꾸로 정렬되었다.
3) 행도 열도 아닌 값(value)을 기준으로 정렬하기 (sort_values)
날짜별지출.sort_values(by='금액')
금액 순서대로 정렬된 것을 확인할 수 있다.
마찬가지로 ascending 옵션을 이용하여 거꾸로 정렬할 수 있다.
날짜별지출.sort_values(by='금액', ascending= False) # 작성할 때 스펠링주의! 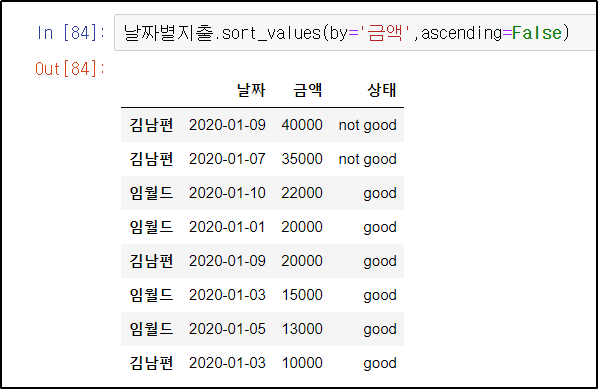
4) 여러개 값(values)을 기준으로 정렬하고 싶을 때는 by옵션에 리스트로 넣어준다.
날짜별지출.sort_values(by=['날짜','금액'])날짜순으로 먼저 정렬하고, 그 다음 금액 순으로 정렬해준다.
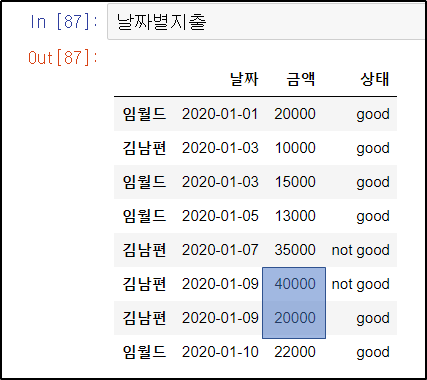
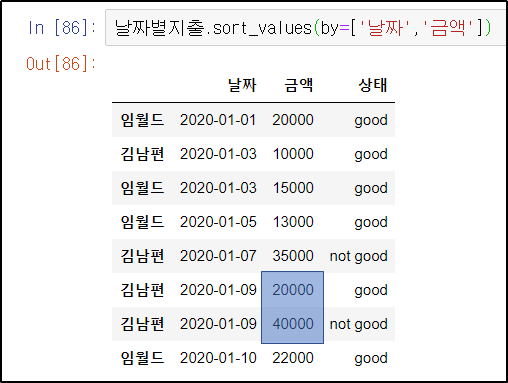
날짜가 같을 때 금액 순으로 정렬이 되었다.
5) 각 values의 오름차순/내림차순을 다르게 하고 싶을 때
날짜별지출.sort_values(by = ["날짜", "금액"], ascending = [True, False])이렇게 하면 날짜는 오름차순, 금액은 내림차순으로 정렬된다.
오늘은 여기까지~
다음에는 간단한 연산과 데이터프레임 색인하는 법을 복습하도록 하자.
'데이터 방' 카테고리의 다른 글
| 판다스로하는 데이터분석 - Series와 DataFrame (0) | 2020.05.10 |
|---|---|
| 매일 파이썬 _ 계산기 만들기 (0) | 2020.01.17 |
| 자기 분석 프로젝트 (0) | 2019.09.18 |
| 워드 클라우드 만들기 (주피터노트북 _ 파이썬) (11) | 2019.07.30 |
| 판다스 데이터 시각화 종류 (기초) _ matplotlib(seaborn) (0) | 2019.07.25 |